Page 1 of 1
Need Help
Posted: Tue Mar 20, 2012 7:02 am
by SueZhaZa
Refer to the image below (data received in.csv file)
Can somebody help me on how to create a subset called 'CostElement' and later insert 2 subsets (Operating Cost and Non-Operating Cost).
For Operating Cost, the should be 4 subsets (Internal Gas Consumption, Plant Utilities, Repair & Maintenance, Material & Supplies)
For Plant Utilities and 'Repair & maintenance', each have one element but for 'Internal Gas Consumption' and 'Material & Supplies', there are still another consolidation then only elements.
The file that i received is in .csv format.
The other concern is; as the above figure, the elements mostly ends at row DESC_L6. There are also possibility that they may have more elements to be added later.
Please help as i am very new to TI programming.
Thank you.
Re: Need Help
Posted: Tue Mar 20, 2012 8:50 am
by declanr
Subsets can not exist within other subset... a subset is merely a view or subsection of elements within a dimension.
Is it the creation of the dimension that you are in fact wanting to achieve (with Operating Cost being a Consolidated element that contains other consolidated elements Internal Gas Consumption etc)?
Re: Need Help
Posted: Tue Mar 20, 2012 9:04 am
by SueZhaZa
sorry for the miscommunication.
Yes, its a dimension called 'CostElement'
within the dimension, there'll be two consolidation Operating Cost and Non-Operating Cost.
The rest will continuously become consolidation until it reaches the last column whereby it will become element.
Please help me with the coding.
Should the coding be under metadata or data?
Re: Need Help
Posted: Tue Mar 20, 2012 9:07 am
by David Usherwood
Metadata.
Re: Need Help
Posted: Tue Mar 20, 2012 9:20 am
by declanr
Changes to structure should be carried out in the metadata tab.
DimensionElementInsert()
DimensionElementComponentAdd()
Can be found in the reference guide and will get you most of the way to what you want to do.
If you intend to run the TI multiple times in order to catch new accounts in the future I would add a simple if statement that checks if the lowest level item exists under the CostElement hierarchy with ELISANC() and if so use the ItemSkip function.
Re: Need Help
Posted: Tue Mar 20, 2012 4:45 pm
by Steve Rowe
The structure of the file you have is an extremely horrid way of describing a dimension structure. Still what can you do that’s not really your problem….
Irrespective of the above I think your TI script looks something like the following. What we are trying to do is work with the columns in pairs and just work with the parent child relationship described. It’s all untested and parsed so it might have a few syntax issues.
You’ll also need to make sure you ignore anywhere the null value is encountered in a field. All the below goes in the Metadata tab once you have set the file up as your datasource, set the field headers up to be variables of the string type and "other"
Code: Select all
sElType=’N’;
sInsertionPoint=’’;
sDimName=’Your Dim Name Here’;
nElWeight=1;
#Parent Child relationship 1
sParent=DESC_L3;
sChild=DESC_L4;
#Check for no Nulls
If ( ~Scan ( ‘Null’ , sParent | sChild ) >0);
DimensionElementInsert(sDimName, sInsertionPoint, sParent, sElType);
DimensionElementInsert(sDimName, sInsertionPoint, sChild, sElType);
DimensionElementComponentAdd(sDimName, sParent, sChild, nElWeight);
EndIf;
#Parent Child relationship 2
sParent=DESC_L4;
sChild=DESC_L5;
#Check for no Nulls
If ( ~Scan ( ‘Null’ , sParent | sChild ) >0);
DimensionElementInsert(sDimName, sInsertionPoint, sParent, sElType);
DimensionElementInsert(sDimName, sInsertionPoint, sChild, sElType);
DimensionElementComponentAdd(sDimName, sParent, sChild, nElWeight);
EndIf;
#Parent Child relationship 3
sParent=DESC_L5;
sChild=DESC_L6;
#Check for no Nulls
If ( ~Scan ( ‘Null’ , sParent | sChild ) >0);
DimensionElementInsert(sDimName, sInsertionPoint, sParent, sElType);
DimensionElementInsert(sDimName, sInsertionPoint, sChild, sElType);
DimensionElementComponentAdd(sDimName, sParent, sChild, nElWeight);
EndIf;
#Parent Child relationship 4
sParent=DESC_L6;
sChild=DESC_L7;
#Check for no Nulls
If ( ~Scan ( ‘Null’ , sParent | sChild ) >0);
DimensionElementInsert(sDimName, sInsertionPoint, sParent, sElType);
DimensionElementInsert(sDimName, sInsertionPoint, sChild, sElType);
DimensionElementComponentAdd(sDimName, sParent, sChild, nElWeight);
EndIf;
Re: Need Help
Posted: Wed Mar 21, 2012 2:18 am
by SueZhaZa
Re: Need Help
Posted: Wed Mar 21, 2012 3:05 am
by Olivier
Subsets can not exist within other subset... a subset is merely a view or subsection of elements within a dimension.
Actually, copying a subset into a subset results in generating a user defined consolidation

This has nothing to do with the original question once decrypted but worth reminding.
Tm1 User guide page 45 :
Adding a User-Defined Consolidation to a Subset
You can create a user-defined consolidation that is different from the consolidations in a dimension
structure. To create a user-defined consolidation, you insert one subset into another subset. The
members of the inserted subset are rolled up into a consolidated element (user-defined consolidation)
that has same name as the source subset. For example, if you insert the subset MySalesArea into
the subset Europe, TM1 adds the user-defined consolidation MySalesArea to Europe
Hope this helps,
Re: Need Help
Posted: Wed Mar 21, 2012 3:40 am
by SueZhaZa
hai,
tried the code.. the error occurs only on the last loop on
Code: Select all
DimensionElementComponentAdd(sDimName, sParent, sChild, nElWeight);
on the last relationship. happens before. not sure why.
attached is the output of the coding... it stills pickup the 'NULL's as element.
Re: Need Help
Posted: Wed Mar 21, 2012 8:04 am
by Andy Key
The Scan function is case sensitive, so replace Null in Steve's code with NULL, clear out your dimension and run the code again.
Re: Need Help
Posted: Wed Mar 21, 2012 8:57 am
by SueZhaZa
Thanks!

btw, i just discover on the ~Scan code..
can someone elaborate more on this?
Re: Need Help
Posted: Wed Mar 21, 2012 9:20 am
by SueZhaZa
Re: Need Help
Posted: Wed Mar 21, 2012 9:27 am
by Alan Kirk
SueZhaZa wrote:Thanks!
btw, i just discover on the ~Scan code..
can someone elaborate more on this?
Scan() is a Rules function that you can use to determine whether one string (a substring) is found inside another string. You can find more about it in the TM1 Reference Guide under Rules Functions -> Text Rules Functions:
SCAN returns a number indicating the starting location of the first occurrence of a specified substring within a given string. If the substring does not occur in the given string, the function returns zero.
SCAN(substring, string)
...
Example
SCAN('scribe', 'described') returns 3.
The tilde (~) in front of it is a logical Not operator. These are described in the section of the Reference Guide titled
Logical Operators in TM1 Rules.
Operator Meaning Example
~ (tilde) NOT ~(Value1 > 5) Equivalent to (Value1 <= 5)
I haven't read through the whole of Steve's code to see exactly what it's doing but when he says:
Code: Select all
If ( ~Scan ( ‘Null’ , sParent | sChild ) >0);
it means this.
TI scans the combined expression sParent | sChild for the word 'Null'. If it finds it, the result will be greater than 0.
However the block of code is only executed if that is NOT true (that is, if you don't find the word Null in there) because of the ~ operator.
Actually you could probably also express this as:
Code: Select all
If ( Scan ( ‘Null’ , sParent | sChild ) =0);
since as far as I know Scan never returns a negative number. (That I'm aware of.)
Edit: Oh dear, I missed the close by moments. No matter, no harm in letting the post stand.

Re: Need Help
Posted: Mon Mar 26, 2012 4:06 am
by SueZhaZa
Thanks Alan!
Great Help!!!

btw.. just wondering, what if the 'NULL' (a string NULL) is a real null value (real blank)... scan doesnt work anymore right?
Re: Need Help
Posted: Mon Mar 26, 2012 4:54 am
by Alan Kirk
SueZhaZa wrote:Thanks Alan!
Great Help!!!
btw.. just wondering, what if the 'NULL' (a string NULL) is a real null value (real blank)... scan doesnt work anymore right?
It's worth bearing in mind that you can't actually get a "null" in a feed to TM1. Null is essentially a relational database concept. Null isn't an empty string (for text fields) and nor is it zero (for numeric fields) it is, in fact, a void; an undefined value. In SQL, Null has been described as something which "sucks the life out of" a value since when you perform any operation against a null field you get... null.
However you can't get real, genuine nulls in an interface to T.I. because it accepts only two data types; strings and numerics. A null which is being fed to a string variable must be reinterpreted as an empty string, and a null which is being fed to a numeric variable must be reinterpreted as a zero.
However your feed is one step removed from a direct feed from the database anyway; it's a .csv, which is by definition pure text. Any nulls need to be converted by the database before it can write such a file. The conversion of a null will typically be to an "empty" field; one where there is nothing between two of the commas. (Not always, of course; in your case the database appears to be converting it to the explicit word "NULL" so that you can identify it as such.)
Although a .csv file is completely text some of the columns, ones which contain text which is in numeric format, can be fed to numeric variables in TI. If a row contains a zero length string, meaning that the file looks something like this, say:
Code: Select all
FirstStringField,NumericField,SecondStringField,ThirdStringField
Description,100,Line1,MoreText
AnotherDesc,,Line2,NumericEmptyHere
ThirdDesc,500,,SecondStringEmptyHere
OneLastDesc,970,Line4,YetMoreTextAgain
Then the NumericField value for Line 2 will be treated as 0, and the SecondStringFiled on line 3 will be interpreted as a zero length string;
"", if you were doing it in VBA, or
'' if you were assigning the value to a user-defined variable in a TI process.
(As an aside, Line2 will be OK if the numeric field is empty as shown above; if it contains text there won't be a conversion to 0, it will instead throw an error.)
However your question is closer to the situation on line 3, where the SecondStringField value is empty. In such a case, yes, the value that comes through into the TI variable will be the equivalent of
'' and you're quite correct that such a value can't be used in a Scan.
Re: Need Help
Posted: Mon Mar 26, 2012 8:43 am
by SueZhaZa
actually the .csv files is for testing purposes..

i just discover that the real procedure is
DIRECTLY from SQL server... with a void, null value (neither string or numeric and yeah as what u explained earlier...)..
from what i understand the SQL server will show 'NULL' for void when doing query in SQL...
and once converted to .csv it will convert from void null to text 'NULL'.
if i'm to test the .csv, by leaving the cell blank, would it be similar to void?


Re: Need Help
Posted: Mon Mar 26, 2012 9:25 am
by Alan Kirk
SueZhaZa wrote:actually the .csv files is for testing purposes..
i just discover that the real procedure is
DIRECTLY from SQL server... with a void, null value (neither string or numeric and yeah as what u explained earlier...)..
from what i understand the SQL server will show 'NULL' for void when doing query in SQL...
and once converted to .csv it will convert from void null to text 'NULL'.
Not exactly. By default when you run a query in SQL Server Management Studio, then any null fields will display with the word "Null". Similarly if you run the query to either Text or to a File (probably the source of your original .csv) then again the word NULL will be displayed, as you've found. There may be a way to override this (other than the obvious one of embedding a Convert command in the original SQL) but I don't know it because to be honest I've never wanted it any other way.
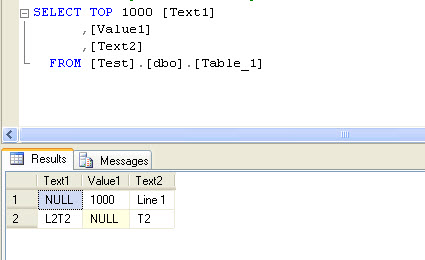
- SQL_1.jpg (21.33 KiB) Viewed 16857 times
However when you use an ODBC connection to pull the same query into TI, the process is smart enough to convert nulls to zero length strings or zero, as the case may be:
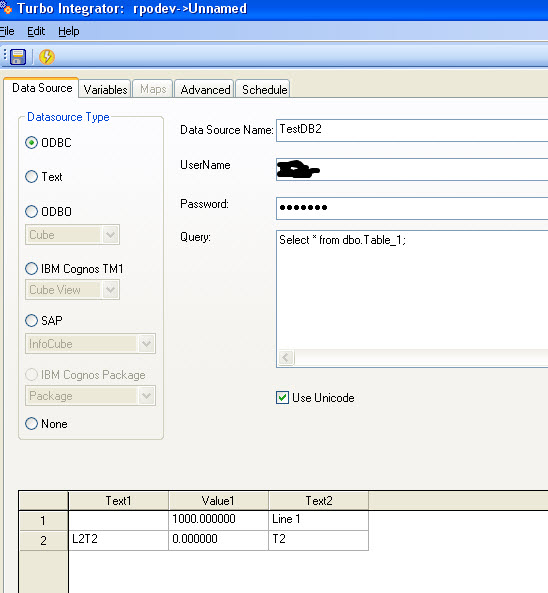
- SQL_2.jpg (64.61 KiB) Viewed 16857 times
Re: Need Help
Posted: Mon Mar 26, 2012 9:40 am
by Alan Kirk
Alan Kirk wrote:By default when you run a query in SQL Server Management Studio, then any null fields will display with the word "Null". Similarly if you run the query to either Text or to a File (probably the source of your original .csv) then again the word NULL will be displayed, as you've found. There may be a way to override this (other than the obvious one of embedding a Convert command in the original SQL) but I don't know it because to be honest I've never wanted it any other way.
Oh, and for the sake of penance for omitting the "obvious" option above (and also because I'm feeling bored at the moment) I'll add that it's the Coalesce function that you can use to generate the output from SQL Server without the word Null. For instance, the code mentioned in the previous post will return zeros and empty strings straight out of SQL server, not just at the TI interface, if coded like this:
Code: Select all
SELECT TOP 1000 COALESCE([Text1],'')
,COALESCE([Value1],0)
,COALESCE([Text2],'')
FROM [Test].[dbo].[Table_1]
In practice though, there's no point doing that if you're doing an ODBC connection since you'll be burning up processor cycles on the SQL server unnecessarily.
Re: Need Help
Posted: Tue Mar 27, 2012 7:44 am
by SueZhaZa
Hi Alan,
Appreciate your post replies!
the thing is now the SQL is none of my business... (haha! its from the client side)
i tried
in order to eliminate any nulls.. so far so good.. as i blank the cell in the csv for testing purposes...
what say you?
would it apply the same to NULL values?