Hi all, Lotsaram,
Bedrock coding is very good. However, there are a couple of reasons/points to note about the usage of Bedrock in real TM1 models at customers:
1. I work for Aexis Belgium rather than Cubewise. Simple. It's not really a good idea if we are going to make publicity for competitors. As a small test, I just downloaded the Bedrock set of processes and did a search on that name:
331 hits in 168 files. EDIT: 186 hits in 89 TI processes in the MAIN folder. You see, I made an error against Git.
2. Bedrock is supposed to reduce the number of lines of coding. Looking at some of those processes, it's really beyond me why someone would ever use processes like "}bedrock.server.wait". Yes, there is logging and a few LogOutput messages. But all those TI processes, in my opinion, clutter up the TM1 server message log. Is said process such an improvement ? Compare:
to:
Code: Select all
ExecuteProcess( '}bedrock.server.wait', 'pLogOutput', 1,
'pStrictErrorHandling', 1,
'pWaitSec', 5
);
I do prefer the first option honestly. Drawing a mindmap of "what process executes what other process(es)" is a complete and utter mess with all the Bedrock processes involved (I wrote a generic TI process to generate such mindmap).
Or, this code:
Code: Select all
ExecuteProcess( '}bedrock.security.refresh', 'pLogOutput', pLogOutput, 'pStrictErrorHandling', pStrictErrorHandling );
and having/writing another process, rather than:
I do agree that most of the processes are useful and have a valid reason to exist.
3. If we refer to people's/company's own reusable libraries, it's certainly not always the same kind of processes. Indeed, it does not make a lot of sense to reinvent the wheel and write again another process to unwind a dimension. Looking at my own processes, they are more involved though. For instance:
- a process to set up a mapping (a custom mapping cube, text elements, custom rules, picklists, read security is applied, views and subsets for input and bad mappings, ...)
- a process to completely identify double countings (nog just the elements with multiple parents)
- a process to check the data source (whatever it is, like the correct number of columns in a text file and abort if not what is expected, etc.)
- a process to set up custom drill-throughs to level 0 in a cube
- a process to convert an Excel file to txt or csv instead of asking the user to do so
This is clearly beyond Bedrock programming. These processes might not be used as often as Bedrock processes but the time saved is so much bigger: they are also targeted to removing manual work for the developer and key admin people, and not only reducing time spent on writing code for the developer.
Below some statistics comparing Bedrock coding against my own TECHnical processes (used very much), other processes that are used less but still generic, and a couple of other ones. I'll leave the analysis for those of you interested. Yes, this cube is created with such a generic TECHnical process.
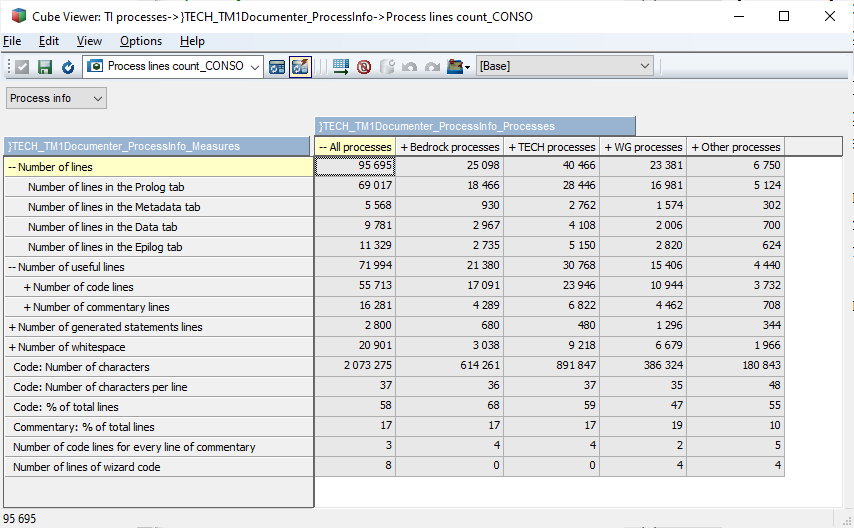
- 01.png (43.29 KiB) Viewed 17611 times
I posted a number of these TECHnical generic processes in the 'Tips and tricks' subforum here, although I tend to work on them and add improvements every once in a while.
Add to this about 46,000 lines of code in Excel VBA (not all TM1 related, though), 11,000 lines of code in Outlook VBA and 8,000 lines of code in AutoHotKey and you will understand that automation and using (reusable) code are important to me (in total about 120,000 lines of code).
4. Where the real power is/can be, is allowing for a parameter like pMode (numeric). A process can be written to create a dynamic level 0 subset. Why not having a parameter for the scope, next to a parameter pName for a text entry:
# The parameter pMode determines to what extend subsets will be created:
# If pMode = 0, you treat all application cubes and dimensions. pName is ignored.
# If pMode = 1, you treat 1 dimension. Specify the dimension name in pName (wildcards * and ? are allowed)
# If pMode = 2, you treat 1 cube. Specify the cube name in pName (wildcards * and ? are allowed)
# If pMode = 3, you treat all dimensions. pName is ignored.
# If pMode = 4, you treat all application dimensions. pName is ignored.
# If pMode = 5, you treat all control dimensions. pName is ignored.
# If pMode = 6, you treat all cubes. pName is ignored.
# If pMode = 7, you treat all application cubes. pName is ignored.
# If pMode = 8, you treat all control cubes. pName is ignored.
# If pMode = 9, you treat a number of control cubes related to security. pName is ignored.
# If pMode = 10, you treat all control cubes related to security. pName is ignored.
# If pMode = 11, you treat a number of control cubes related to statistics. pName is ignored.
# If pMode = 12, you treat all measures dimensions. pName is ignored.
# If pMode = 13, you treat all dimensions specified in a subset called 'auto subsets' (hard-coded value in this process). pName is ignored.
# If pMode = 14, you treat all cubes specified in a subset called 'auto subsets' (hard-coded value in this process). pName is ignored.
For an experienced TM1 developer, writing this is not the end of the world, but it can be useful. Or allow for a parameter pLanguage since not all of us speak English. A Default view is called like that in English, but it will not show up as Default if the user has a different UI language like French.
https://www.wimgielis.com/tm1_userinter ... ges_EN.htm
5. In real life TM1 models, we (I) very often see that a generic process just does not fit in perfectly. More often than not, a process needs to do "almost" what the generic process does, but also needs to do a few other things (like updating an attribute for instance). We can change the generic process but then we deviate from the Bedrock coding, so in the end we give up and switch to a new process.
6. Some processes are just too "heavy", in the sense that they can do so much, but using them for simple tasks will actually lead to slower executions. For example, I can imagine that a generic copy process with all kind of checks and also IF-structures to check for the number of dimensions, will/can be slower than just doing the CellIncrementN in the data tab of a process. I did not test this, but I am confident that this can be the case.
7. I do appreciate a platform like Git. The cons that have been talked about, they do not outweight the pros, at least not in my opinion. I prefer this solution rather than the old static website for Bedrock, even though I had to learn some Git skills too.
8. (I add this point number 8 some time later) What I notice in my own reusable library: there are a lot of parameters and functionality in the processes. It allows for a big number of possible combinations, given parameter values. Testing the processes is not always the most interesting part of the job (sigh) and we all know what that means or can mean. From time to time it happens that I run into an error at the customer site, fix it very quickly or just do the task manually, and the real check/test happens a couple of evenings later. My processes become bigger, and this problem is likely to occur more and more. Certainly with new core server additions like hierarchies. The pMode example above actually should be extended for hierarchies... it becomes a never-ending story even just to follow up.





 It was meant to be funny
It was meant to be funny  and certainly not as viable option beyond any work done for fun or demo purposes.
and certainly not as viable option beyond any work done for fun or demo purposes.